Data Pipelines and Why to Use Them
Data pipelines
Data pipelines are the foundation of automation. They're programs that are called according to schedules, and they collect, merge, transform, and store data automatically.
Pipelines make it possible to:
- Parse data on the Internet and store the results in a database
- Collect information on the visits and purchases of various users from corporate systems and build reports for further cohort analysis
- Detect anomalies in user behavior
- Analyze A/B tests
- Send information to your teammates about growth in sales and visits
And all without lifting a human finger! Just robot fingers.
The stages of a pipeline can be described with the acronym ETL: extract, transform, load.
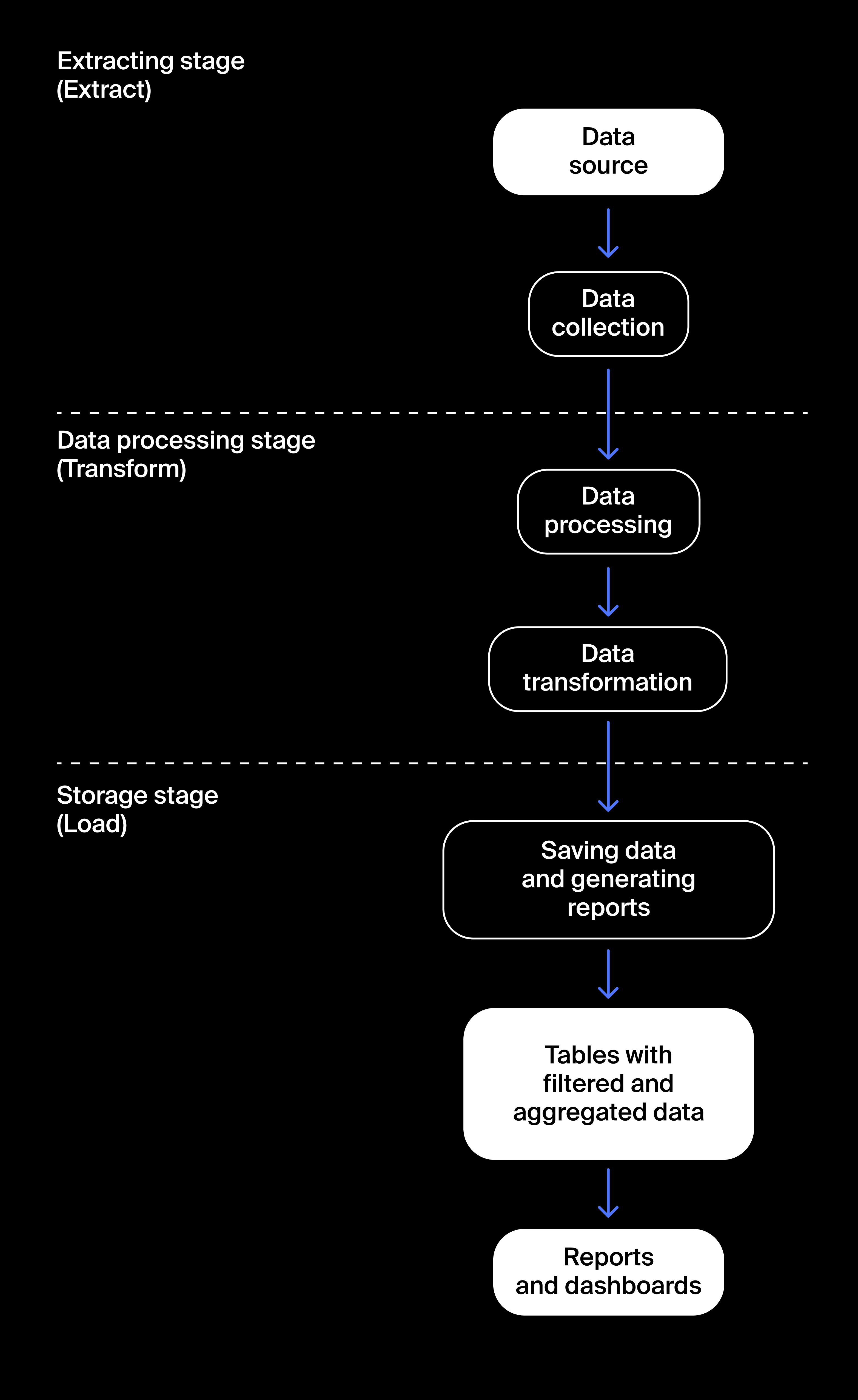
In the extract stage, pipelines collect data from various sources, such as websites, databases of the company and its partners, and external APIs.
In the transform stage, the collected data is first standardized and then categorized. After categorization, the data is transformed or converted to a format convenient for building reports or storing aggregated information. At this stage you could transform the data on visits into tables, where LTV is calculated for an eventual cohort analysis.
In the load stage, pipelines save the aggregated data in database tables and build reports and mailouts.
Data pipelines are designed in such a way that all their stages can be launched over and over, producing consistent results.
Aggregating Data and Creating Tables in Databases
The source data for analysis is typically stored in databases, usually in unprocessed logs (records of events).
Fortunately, analysts rarely need raw data, as aggregated data suffices for reports and conclusions. Aggregation is the process of grouping data and making it smaller in size.
Reading millions of records from a database can take hours! It's better to make a new table where you'll store data grouped by month and country.
To store aggregated data, you'll need to create a table in psql using the CREATE TABLE command. Which looks like this:
1CREATE TABLE table_name (primary_key data_type,2 column_name1 data_type,3 column_name2 data_type,4 …);
PostgreSQL has loads of various data types. But we'll only need the basics.
INT— integerREAL— floating point numberVARCHAR(n)— a string, where n is the maximum length. For example,VARCHAR(128)is for a field containing a string no longer than 128 charactersTIMESTAMP— date and timeSERIAL— a special data type for primary key values. Remember that a primary key is the unique number of a table record. The primary key is defined with the following expression:
1CREATE TABLE table_name (primary_key_field_name serial PRIMARY KEY);
When you add a new record to the table, the DBMS assigns it a row number that's 1 greater than the preceding one and places this number in a field with the type SERIAL.
Vertical and Horizontal Tables
When designing aggregate tables always try to make them vertical, so that each element of the data has its own column. When things are arranged like this, automation and scaling become much easier.
Using horizontal tables can lead to problems. Each time you add a new column to the pipeline, as well as to dashboards and reports connected to it, you'll have to define the column type and the rules for processing missing values. You can do this in the code, of course, but it's a lot simpler just to create a table of the first type. You won't have to redefine their structures if you decide to add new data.
Something may go wrong when you create tables. It could turn out that the table needs a different structure. Don't worry! Just delete it in psql with the DROP TABLE command:
1DROP TABLE table_name;
Once you've deleted the incorrect tables and left the ones you need, it's time to grant access to it in psql. To do so, use the GRANT command:
1GRANT ALL PRIVILEGES ON TABLE agg_games_year TO anthony;2-- here anthony is the name of a user who wants access to the table
TOdefines the user who will be given permissionON TABLEindicates the table for which access is to be providedALL PRIVILEGESmeans that the user gets all possible permissions for working with the table: they can read, write, and delete data
In addition to access rights, you also need to provide permissions to work with primary keys. When you create a SERIAL field with primary keys, the DBMS automatically creates a SEQUENCE object, which stores data on the way primary key identifiers should be generated. These objects are automatically assigned names that look like tableName_keyName_seq.
1GRANT USAGE, SELECT ON SEQUENCE table_name_id_seq TO anthony;
GRANT USAGE means that the user can now add new values to agg_games_year_record_id_seq.
GRANT SELECT allows the user to read data from the table.
Creating a Pipeline Script
Although your teammates can always provide you with dump files, you should always try to get direct access to databases.
- Since you won't have to wait until a dump is ready, you'll be able to speed up your work.
- Automation is impossible without direct access to data. If your teammate gets sick or goes on vacation without creating a dump file for you, the automation process will fail.
- You can find lots of interesting things in databases.
The SQLAlchemy library lets you read data from database tables into pandas DataFrames and store data from pandas in a database with just one command.
We'll connect to the database using sqlalchemy. Let's create a script in Sublime Text:
1#!/usr/bin/python23# Importing libraries4import pandas as pd5from sqlalchemy import create_engine67# Defining parameters for connecting to the database;8# you can request them from the database administrator.9db_config = {'user': 'my_user', # username10 'pwd': 'my_user_password', # password11 'host': 'localhost', # server address12 'port': 5432, # connection port13 'db': 'games'} # database name1415# Creating the database connection string.16connection_string = 'postgresql://{}:{}@{}:{}/{}'.format(db_config['user'],17 db_config['pwd'],18 db_config['host'],19 db_config['port'],20 db_config['db'])21# Connecting to the database.22engine = create_engine(connection_string)2324# Creating an SQL query.25query = ''' SELECT game_id, name, platform, year_of_release26 FROM data_raw27 '''2829# Running the query and storing the result30# in the DataFrame.31# SQLAlchemy will automatically give the columns32# the same names that they have in the database table. We'll just have to33# specify the index column using index_col.34data_raw = pd.io.sql.read_sql(query, con = engine, index_col = 'game_id')3536print(data_raw.head(5))
Let's study this code in detail. To connect to a database, you need to specify:
- a DBMS
- Database location: the IP address of the server where the database is deployed, and the port to be connected
- Username and password for connection
- The name of the database you need (one server can store multiple databases)
SQLAlchemy automatically analyzes whether the primary keys of a database table and the DataFrame indices are the same. SQLAlchemy is guided by the if_exists parameter. If you specify
if_exists = 'replace', SQLAlchemy will clear the existing data from the table and save the new data. If you indicate if_exists = 'append', SQLAlchemy will add new rows to the end of the table.
1df.to_sql(name = 'table_name', con = engine, if_exists = 'append', index = False))
Sometimes you'll need to delete older rows from the table as your pipeline runs. To do so, use the special SQL command DELETE:
1DELETE FROM table_name WHERE conditions_for_finding_records_to_be_deleted;