Language Representations
Word embeddings
Language models transform text into vectors and use a set of techniques which are collectively called word embeddings.
A vector made from a word using word embedding will carry some contextual information about the word and its semantic properties.
Semantic properties are the components of a word that contribute to its meaning. The word "sailor" has the following semantic properties: "male," "occupation," "person," "naval." These properties distinguish the word "sailor" from other words.
This concept allows for working with words in their vectorized form while still keeping the context in mind. This means that words with similar contexts will have similar vectors. The distance (cosine, euclidean, etc.) between the vectors is a common measure of their similarity.
Word2vec
Another thing word2vec can do is train a model to distinguish pairs of true neighbors from random ones. This task is like a binary classification task, where features are words and the target is the answer to whether or not the words are true neighbors.
Embeddings for classification
Let's say there is a text corpus that needs to be classified. In that case, our model will consist of two blocks:
- Models for converting words into vectors: words are converted into numerical vectors.
- Classification models: vectors are used as features.
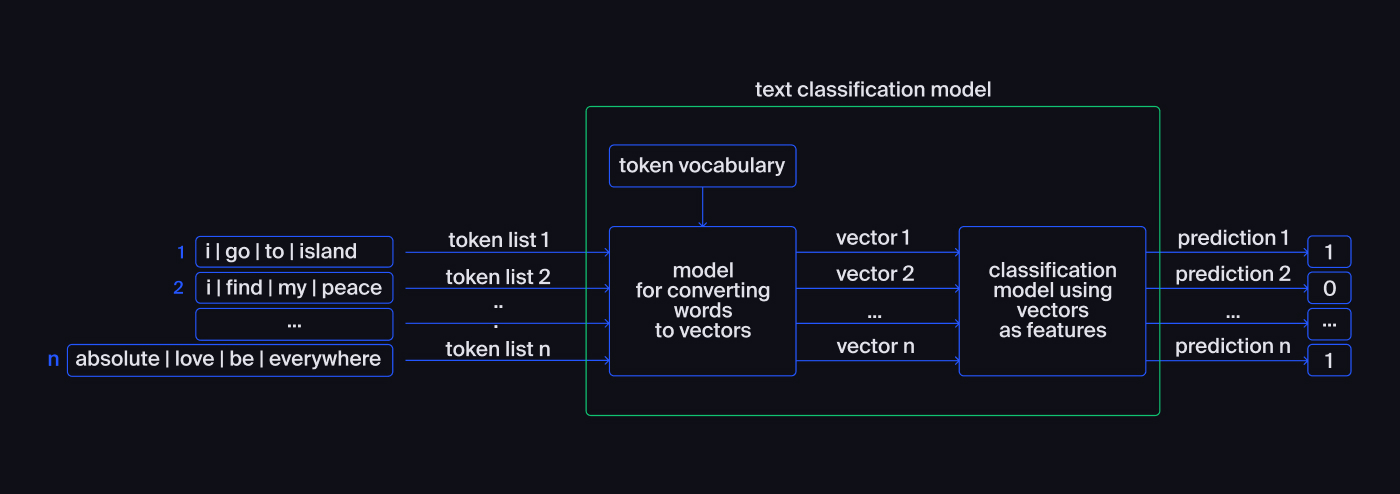
Let's walk through the details:
Before moving on to the vectorization of words, we need to perform the preprocessing.
- Each text is tokenized
- Then the words are lemmatized
- The text is cleaned of any stop words or unnecessary characters
- For some algorithms special tokens are added to mark the beginning and end of sentences.
Each text acquires its own list of tokens after preprocessing.
Then tokens are passed to the model, and the model vectorizes them by using a pre-compiled token vocabulary. At the output, we get vectors of predetermined length formed for each text.
The final step is to pass the features to the model. The model then predicts the tonality of the text: "0" — negative, or "1" — positive.
BERT
BERT (Bidirectional Encoder Representations from Transformers) is a neural network model created for language representation.
BERT is an evolutionary step when compared to word2vec. The most accurate models today are BERT and GPT-3 .

When processing words, BERT takes into account both immediate neighbors and more distant words. This allows BERT to produce accurate vectors with respect to the natural meaning of words.
BERT and preprocessing
We are going to solve a classification task for movie reviews by using BERT language representation. We're going to take a pre-trained model called bert-base-uncased (trained on lowercased English texts).
1import torch2import transformers
BBERT has its own tokenizer based on the corpus it was trained on. Other tokenizers won't work with BERT, and lemmatization is not required.
Preprocessing steps for the text:
Initialize the tokenizer as an instance of
BertTokenizer()with the name of the pre-trained model.1tokenizer = transformers.BertTokenizer.from_pretrained('bert-base-uncased')Convert the text into IDs of tokens, and the BERT tokenizer will return IDs of tokens rather than tokens:
1example = 'It is very handy to use transformers'2ids = tokenizer.encode(example, add_special_tokens=True)3print(ids)We get:
1[101, 2009, 2003, 2200, 18801, 2000, 2224, 19081, 102]To operate the model correctly, we set the
add_special_tokensargument toTrue. It means that we added the beginning token (101) and the end token (102) to any text that's being transformed.BERT accepts vectors of a fixed length. If there are not enough words in an input string to fill in the whole vector with tokens (or, rather, their identifiers), the end of the vector is padded with zeros. The input string is either limited to the size of 510 or some identifiers returned from
tokenizer.encode()are usually skipped, e.g. all identifiers after the position 512 in the list:1```python2n = 51234padded = np.array(ids[:n] + [0]*(n - len(ids)))56print(padded)7```89We get:1011```plain12[101 2009 2003 2200 18801 2000 2224 19081 102 0 0 0 0 ... 0 ]13```1415Now we have to tell the model why zeros don't carry significant information.1617```python18attention_mask = np.where(padded != 0, 1, 0)19print(attention_mask.shape)20```2122We get:2324```plain25(512, )26```
BERT embeddings
Initialize the BertConfig configuration. Pass it a JSON file with the model settings description. JSON is a keyed stream of numbers, letters, colons, and braces that returns a server when called.
Initialize the model of BertModel class. Pass the file with the pre-trained model and configuration:
1config = BertConfig.from_pretrained('bert-base-uncased')2model = BertModel.from_pretrained('bert-base-uncased')
Let's start by converting texts into embeddings. It may take several minutes, so engage the tqdm library to displays the progress of the operation. In Jupyter use the notebook() function.
1from tqdm.auto import tqdm
The BERT model creates embeddings in batches. Make the batch size small so that the RAM won't be overwhelmed:
1batch_size = 100
Make a loop for the batches. The notebook() function will indicate the progress:
1# creating an empty list of review embeddings2embeddings = []34for i in tqdm(range(len(ids_list) // batch_size)):5 ...
Transform the data into a tensor format. Tensor is a multidimensional vector in the torch library.
LongTensor data type stores numbers in the "long format," that is, it allocates 64 bits for each number.
1# putting together vectors of ids (of tokens) to a tensor2ids_batch = torch.LongTensor(ids_list[batch_size*i:batch_size*(i+1)])3# putting together vectors of attention masks to a tensor4attention_mask_batch = torch.LongTensor(attention_mask_list[batch_size*i:batch_size*(i+1)])
Pass the data and the mask to the model to obtain embeddings for the batch:
1batch_embeddings = model(ids_batch, attention_mask=attention_mask_batch)
Use the no_grad() function to indicate that we don't need gradients in the torch library. It will make calculations faster.
1with torch.no_grad():2 batch_embeddings = model(ids_batch, attention_mask=attention_mask_batch)
Extract the required elements from the tensor and add the list of all the embeddings:
1# converting elements of tensor to numpy.array with the numpy() function2embeddings.append(batch_embeddings[0][:,0,:].numpy())
Putting all the above together, we get this loop:
1batch_size = 10023embeddings = []45for i in tqdm(range(len(ids_list) // batch_size)):67 ids_batch = torch.LongTensor(ids_list[batch_size*i:batch_size*(i+1)])8 attention_mask_batch = torch.LongTensor(attention_mask_list[batch_size*i:batch_size*(i+1)])910 with torch.no_grad():11 batch_embeddings = model(ids_batch, attention_mask=attention_mask_batch)1213 embeddings.append(batch_embeddings[0][:,0,:].numpy())
Call the concatenate() function to concatenate all the embeddings in a matrix of features:
1features = np.concatenate(embeddings)